引言 HashMap是Java程序员使用频率最高的一种映射(<Key,Value>键值对)数据结构,它继承自AbstractMap,又实现了Map类。
本文将深入源码解析一下HashMap的底层原理。
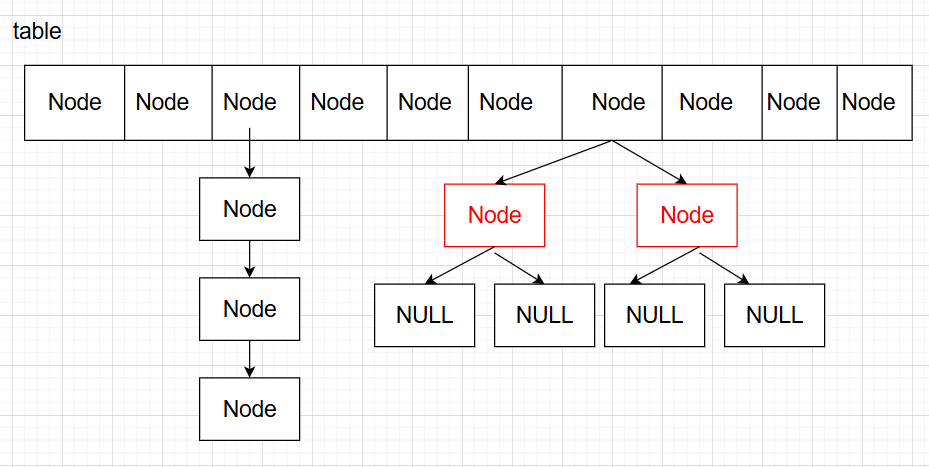
数据结构 HashMap底层通过维护一个table数组来实现:
1 transient Node<K,V>[] table;
table数组里面的元素是一个Node类,用于存储每个键值对。
Node类是HashMap的一个静态内部类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 static class Node <K,V> implements Map .Entry<K,V> {final int hash;final K key;int hash, K key, V value, Node<K,V> next) {this .hash = hash;this .key = key;this .value = value;this .next = next;public final K getKey () { return key; }public final V getValue () { return value; }public final String toString () { return key + "=" + value; }public final int hashCode () {return Objects.hashCode(key) ^ Objects.hashCode(value);public final V setValue (V newValue) {V oldValue = value;return oldValue;public final boolean equals (Object o) {if (o == this )return true ;if (o instanceof Map.Entry) {if (Objects.equals(key, e.getKey()) &&return true ;return false ;
可以看到,在Node类中维护了每个键值对的哈希值:hash,Key值:key,Value值:value,以及用于维护链表或者红黑树(JDK1.8)的下一个Node:next。
在理想情况下(没有哈希冲突)HashMap的操作时间复杂度可以达到O(1)。为了解决哈希冲突(也就是哈希值重复)的问题,HashMap在table数组中将哈希冲突的Node结点维护成链表或者红黑树。在JDK1.8前(不含JDK1.8),HashMap的数据结构是数组+链表,在JDK1.8及以后优化为数组+链表+红黑树。
图中红黑树并不规范,仅作参考。
在JDK1.7及之前,对于哈希冲突的不同键值对结点,仅将它们维护成一个链表,而对于一个链表的操作,时间复杂度是O(n),大大影响了HashMap理想情况下O(1)的时间复杂度。因此,在JDK1.8及之后,增加的红黑树来优化,红黑树是一种平衡二叉搜索树,操作的时间复杂度为$O(log_n)$,在元素多的情况下,远优于O(n):
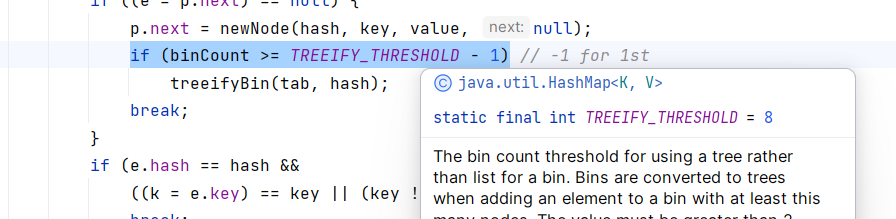
可以看到,在ptuVal方法中,如果链表结点数量超过7(因为一般情况下,链表节点数超过7,性能就会大幅下降),就会树化,调用treeifyBin函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 final void treeifyBin (Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)else if ((e = tab[index = (n - 1 ) & hash]) != null ) {null , tl = null ;do {null );if (tl == null )else {while ((e = e.next) != null );if ((tab[index] = hd) != null )
treeifyBin函数会将链表树化,但是,在这之前:
可以看到,会先监测数组长度,当数组长度小于64时并不会数化,而是调用resize方法进行扩容!为什么呢?
这是由于当数组长度较小时,哈希冲突率较高,会产生较多的长链表,那么也就会频繁的执行数化操作,此外树结构会比链表占用更多的空间,而且,对于短数组,大概率会在不久的将来执行扩容操作,又会将树进行拆分,故而,选择在数组长度较小时执行扩容操作。
Hash方法 当我们使用put方法向HashMap中加入一个键值对时:
1 2 3 public V put (K key, V value) {return putVal(hash(key), key, value, false , true );
在put方法内调用了putVal方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 final V putVal (int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {int n, i;if ((tab = table) == null || (n = tab.length) == 0 )if ((p = tab[i = (n - 1 ) & hash]) == null )null );else {if (p.hash == hash &&null && key.equals(k))))else if (p instanceof TreeNode)this , tab, hash, key, value);else {for (int binCount = 0 ; ; ++binCount) {if ((e = p.next) == null ) {null );if (binCount >= TREEIFY_THRESHOLD - 1 ) break ;if (e.hash == hash &&null && key.equals(k))))break ;if (e != null ) { V oldValue = e.value;if (!onlyIfAbsent || oldValue == null )return oldValue;if (++size > threshold)return null ;
可以看到,在putVal方法中会根据hash (key)生成的hash值来计算Node在table数组中的位置索引。
也就是通过(n - 1) & hash来计算Node的位置索引,hash就是通过hash方法算出的哈希值,n就是table数组的长度(元素个数)。
那么为什么通过(n - 1) & hash来计算Node的索引呢?
我们知道,对于一个数集[0,1,2,…,k],如果想要让一个非负数数据集B内的数据全部映射到A内,可以通过取余运算来完成:B[i] % (k+1)
此时,如果(k+1)为2的n次方,那么B[i] % (k+1)=B[i] & k。
也就是说,如果table的长度n为2的某个次方,那么(n - 1) & hash等价于hash%n,又因为对于二进制的计算机来说,位运算是比取余运算更快的,所以这里巧妙的采用(n - 1) & hash来计算Node的索引。
我们知道了hash值的作用,是用来确定Node在table数组中的位置的,接下来让我们看看hash方法是怎么算出hash值的:
1 2 3 4 static final int hash (Object key) {int h;return (key == null ) ? 0 : (h = key.hashCode()) ^ (h >>> 16 );
可以看到,如果key值不为空的话,将会通过key的哈希码和key的哈希码逻辑右移16位后的值进行异或运算:(h = key.hashCode()) ^ (h >>> 16)
哈希码是通过key对象本身的Object.hashCode()方法得到的。
对于将key的哈希码逻辑右移16位,我们可以看到h也就是key的哈希码是int类型的,占32位,逻辑右移16位后得到其高16位。也就是将key哈希码的高16位与低16位进行异或运算,作用是使hash值更均匀分散,降低哈希冲突率。
此外,当两个数据哈希冲突时,会根据equals方法来判断,如果相等,则直接覆盖原数据,如果不等,则维护成链表或红黑树(JDK1.8及以后)。
1 2 3 4 5 6 7 8 9 10 11 12 public final boolean equals (Object o) {if (o == this )return true ;if (o instanceof Map.Entry) {if (Objects.equals(key, e.getKey()) &&return true ;return false ;
扩容机制 我们在构建HashMap时,可以通过构造函数传参来自定义初始容量和负载因子:
1 public HashMap (int initialCapacity, float loadFactor) {...}
HashMap的最大容量是2的30次方:
1 static final int MAXIMUM_CAPACITY = 1 << 30 ;
HashMap给的默认初始容量是16:
1 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4 ;
那么,什么时候需要扩容呢?
HashMap会在容量大于阈值时触发扩容机制,这个阈值是由容量与负载因子的乘积求得的,负载因子loadFactor的默认值为0.75:
1 static final float DEFAULT_LOAD_FACTOR = 0.75f
那么,为什么加载因子是0.75呢?
加载因子是用来表示HashMap中数据的填满程度的,也就是说,加载因子=HashMap中数据的个数/HashMap的容量,根据这个公式,可得:
加载因子越大,空间利用率就越高,但是哈希冲突率也会越高
加载因子越小,哈希冲突率就越低,但是空间利用率也会越低
鱼与熊掌不可兼得!这就必须要求我们取一个中庸之值,至于如何取得0.75这个值,这里面涉及了泊松分布和指数分布等统计与概率学的知识,大家感兴趣自行研究!
如果HashMap的数据量超过了阈值,就会调用resize()方法进行扩容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 final Node<K,V>[] resize() {int oldCap = (oldTab == null ) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0 ;if (oldCap > 0 ) {if (oldCap >= MAXIMUM_CAPACITY) {return oldTab;else if ((newCap = oldCap << 1 ) < MAXIMUM_CAPACITY &&1 ; else if (oldThr > 0 ) else { int )(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);if (newThr == 0 ) {float ft = (float )newCap * loadFactor;float )MAXIMUM_CAPACITY ?int )ft : Integer.MAX_VALUE);@SuppressWarnings({"rawtypes","unchecked"}) new Node [newCap];if (oldTab != null ) {for (int j = 0 ; j < oldCap; ++j) {if ((e = oldTab[j]) != null ) {null ;if (e.next == null )1 )] = e;else if (e instanceof TreeNode)this , newTab, j, oldCap);else { null , loTail = null ;null , hiTail = null ;do {if ((e.hash & oldCap) == 0 ) {if (loTail == null )else else {if (hiTail == null )else while ((e = next) != null );if (loTail != null ) {null ;if (hiTail != null ) {null ;return newTab;
扩容机制会有以下几个主要流程:
如果已经超过了HashMap最大容量MAXIMUM_CAPACITY ,就不再扩容,将阈值设为Integer.MAX_VALUE (2的31次方减1),直接返回。
将数组table容量扩大两倍,由于Java没有动态数组,需要新创建一个两倍大小的数组,然后再将原数组中的数据都移至新数组。
将数据从原数组移至新数组时,在JDK1.8之前需要重新计算hash值,重新确定数组索引位置;在JDK1.8及以后,为了使数据更分散,对于链表数据的索引做了优化:我们通过(n - 1) & hash来计算索引位置,由于数组长度n是2倍扩展,所以新的(n-1)比旧的(n-1)只是高位多了一个1,结果就是:如果hash不变的情况下,
若hash多出来的高位是1,那么计算出来的新索引刚好就是原索引值+原数组长度
若hash多出来的高位是0,那么索引不变。
优化以后,转移链表数据至新数组时,就不用再重新计算hash值,提高了效率。
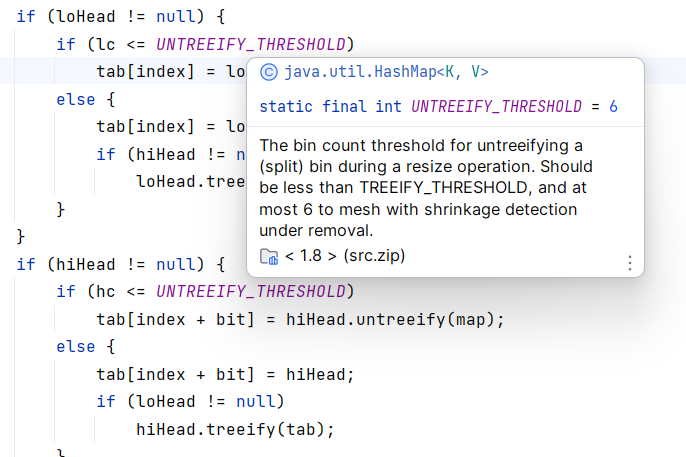
对于红黑树,会通过split方法,将其拆分为新树或链表:
1 2 else if (e instanceof TreeNode)this , newTab, j, oldCap);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 final void split (HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {this ;null , loTail = null ;null , hiTail = null ;int lc = 0 , hc = 0 ;for (TreeNode<K,V> e = b, next; e != null ; e = next) {null ;if ((e.hash & bit) == 0 ) {if ((e.prev = loTail) == null )else else {if ((e.prev = hiTail) == null )else if (loHead != null ) {if (lc <= UNTREEIFY_THRESHOLD)else {if (hiHead != null ) if (hiHead != null ) {if (hc <= UNTREEIFY_THRESHOLD)else {if (loHead != null )
可以看到,调用split方法重构树时,如果树的结点数小于等于6,就会调用untreeify方法进行链表化,这是因为,当结点数小于等于6时,树提供的操作效率已经无法弥补它占用的大量空间,此时需要对时间与空间进行妥协,将树转为链表。那么为什么是小于等于6,而不是小于等于7呢?
这是为了留个缓冲余地,避免结点数在7、8之间频繁切换导致链表与树的频繁转化,导致性能的浪费。
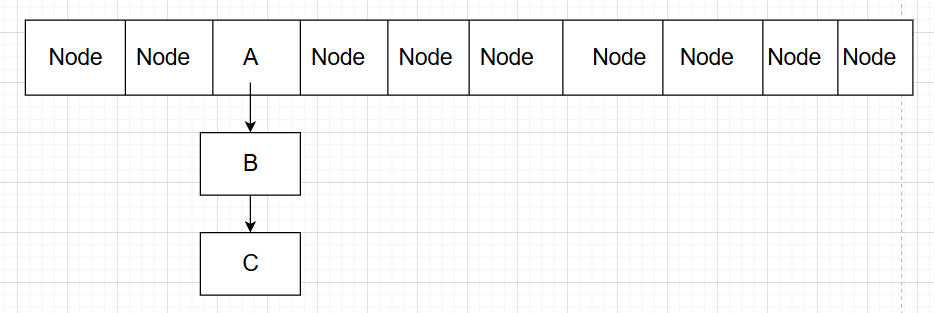
多线程 JDK1.7及其之前,多线程的情况下,在扩容时,链表在从旧数组转移到新数组时可能会产生死循环的问题(转移链表时采用的是单指针头插法):
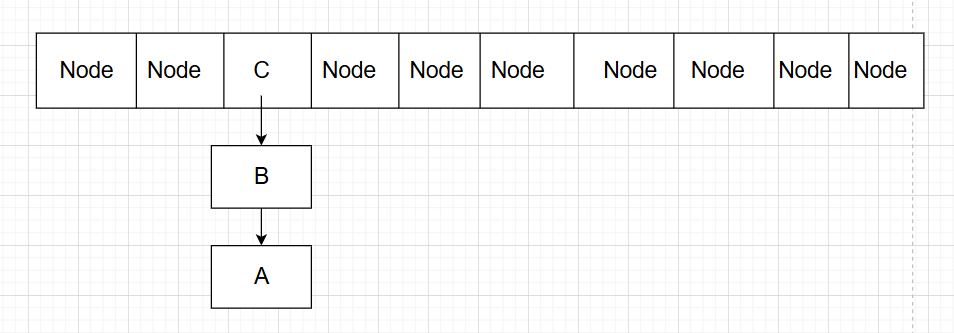
对于链表A->B->C:
线程P1刚要开始迁移,让指针p指向A,此时,线程P1的时间片用完,CPU调度线程P2开始执行。
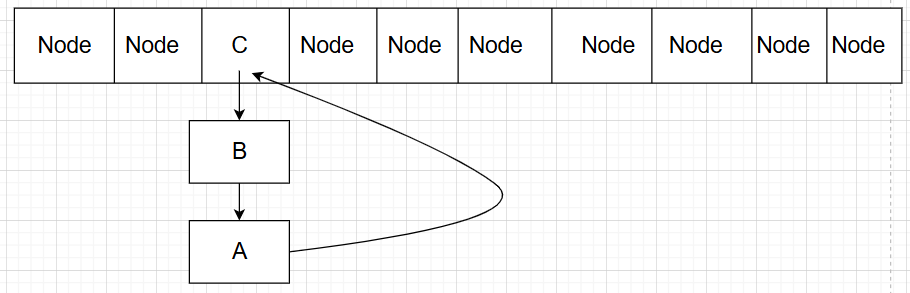
线程P2完整执行了整个链表迁移工作,使链表变成:
此时,CPU调度线程P1继续执行:
1 2 3 p.next = newTable[i];
由于新链表头结点已经由null转变成了C,导致A与C结点构成了循环:
JDK1.8及其之后,虽然通过双指针尾插法消除了这个问题,但依然存在其它线程安全问题,在多线程的环境下,我们应该使用线程安全的ConcurrentHashMap类。